Le reste des séances a été consacré à la réalisation du script nous permettant d’étudier le mot choisi dans nos langues. Ce script nous permet d’aspirer des pages web préalablement sélectionnées selon notre mot, puis d’en faire des dumps en utf-8, entre autres. Ceci nous permet à la fin de constituer un corpus par langue.
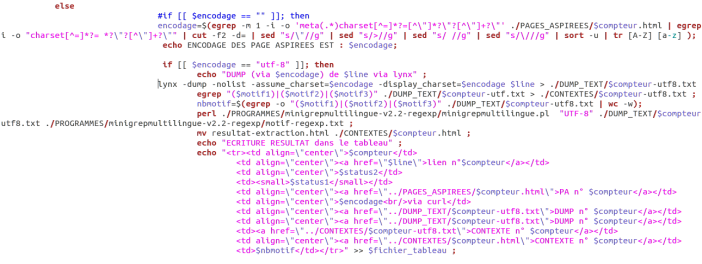
Le début du script permet d’aller chercher les fichiers contenant les URLS, et de sélectionner les motifs à rechercher dans les dump_text créés. Un tableau est créé par fichier d’URLS.
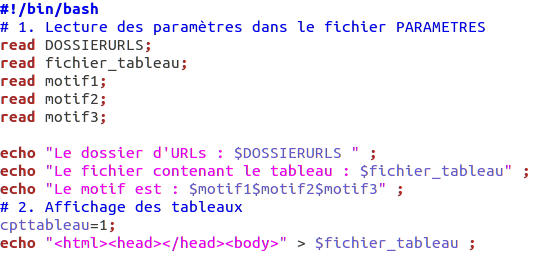
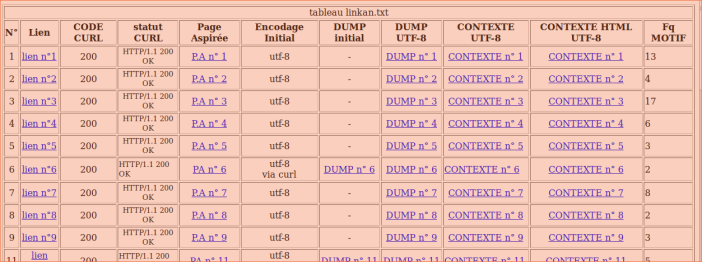
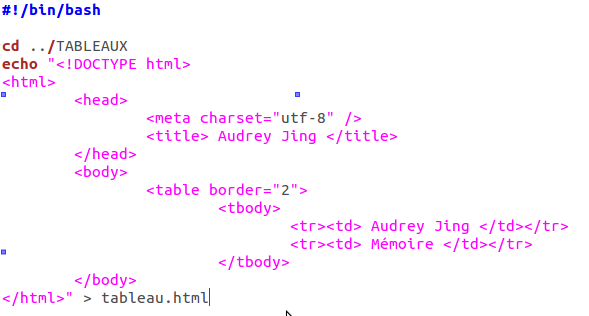
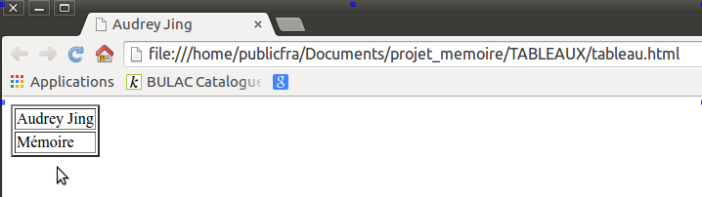
La première grande partie du script est constituée ainsi. Pour chaque fichiers d’URLS contenus dans le répertoire /URLS, un tableau est créé. <tr> </tr> permet de créer une nouvelle ligne, <td> </td> une nouvelle colonne.
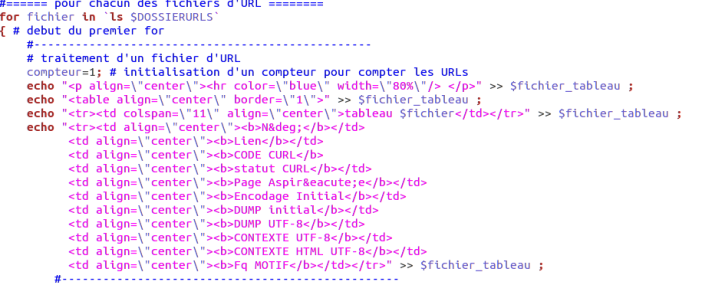
Après avoir créer le tableau, les pages URLS sont aspirées vers le répertoire /PAGES_ASPIREES à l’aide de la commande curl. Le bon déroulement du téléchargement est ensuite vérifié.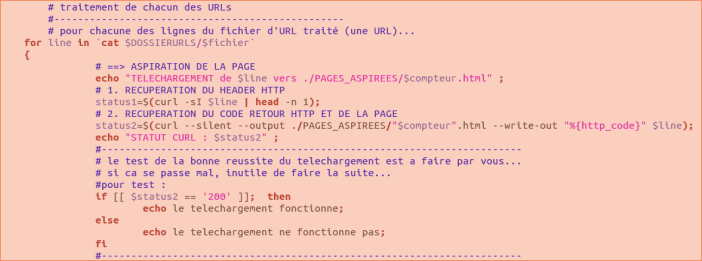
Une fois la page aspirée, l’encodage est recherché, ici à l’aide de la commande egrep. Sa valeur est attribué à la variable $encodage.
Si l’encodage est trouvé dans la page:
1. L’encodage est utf-8, alors le dump de la page est créé via lynx.
Ensuite, le motif est recherché dans le dump créé à l’aide de la commande egrep. Les lignes reconnues sont ainsi envoyées dans un fichier dans le répertoire CONTEXTES. Le nombre de fois où est exprimé le motif est également compté. Les résultats sont ensuite écrits dans le tableau.
Le programme perl minigrepmultilingue.pl permet de créer un fichier contexte enrichi. Le motif est mis en avant et est bien structuré.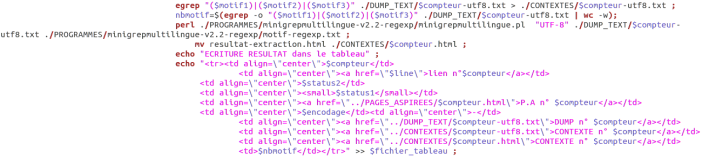
2. Si l’encodage n’est pas utf-8, le dump de la page est créé puis l’encodage de la page, s’il est connu de la commande iconv, est convertit en utf-8. Un autre dump de la page mais cette fois en encodage utf-8 est créé. Ensuite, le motif entré avant l’exécution du script est recherché dans les dumps en utf-8. de même que précédemment, les lignes reconnues sont envoyées dans un fichier dans le répertoire CONTEXTES. Le nombre de fois où est exprimé le motif est également compté. Les résultats sont ensuite écrits dans le tableau.
Le programme perl minigrepmultilingue.pl permet de créer un fichier contexte enrichi. Le motif est mis en avant et est bien structuré.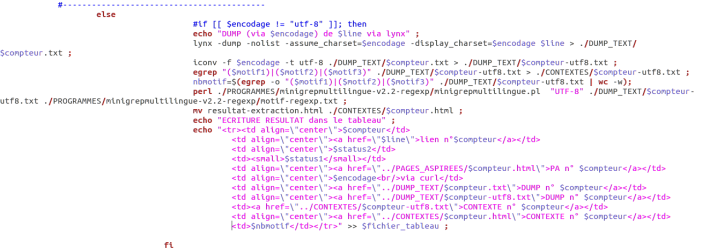
Si la recherche d’encodage n’a rien donné, le charset de la page est recherché à l’aide d’une expression régulière que nous pouvons observer ci-dessous.
Une fois l’encodage de la page extrait, les étapes 1. et 2. précédemment expliquées se répètent.